
Acknowledgements
This brief note is a summary of a proposal submitted to the National Science Foundation. I first acknowledge this support and my co-PIs: Haijun Xia and Philip Guo at UC San Diego, Arvind Satyanayaran at MIT, and Maneesh Agrawala at Stanford. I also would like to acknowledge the members of the project advisory panel: Saadi Lahlou (LSE and Paris-IEA), Wendy Mackay (Inria), Tom Malone (MIT), Gary Olson (UCI), Roy Pea (Stanford), Justin Solomon (MIT), and Jaime Teevan (Microsoft). In addition, the proposal is strengthened by the involvement of the Human-Computer Interaction Consortium (hcic.org), the Paris Institute for Advanced Study (paris-iea.fr), organizations with extensive experience with both interdisciplinary research and interactions across multiple institutions, the French eNSEMBLE network, and Microsoft Future of Work network. Michel Beaudouin-Lafon (Universit'e Paris-Saclay) will serve as the representative from the eNSEMBLE network and Abigale Sellen from the Microsoft Future of Work network.
This paper was written during a 1-month residence at the Paris Institute for Advanced Study under the "Paris IAS Ideas" program.
Barbara Tversky in her delightful and informative book, Mind in Motion (Tversky, 2019), tells us that when thought overruns the mind we put it in the world. We jot thoughts on pieces of paper, whiteboards, and post-it notes. We type them into laptops and phones, highlight them in books and articles by underlining or making margin notations, and surprisingly often send them in emails to ourselves. Even if captured, we face the problem of finding them when needed. Physical media can only be in one place and often that is not where we are. If we store them in the cloud we need network access and they are often still difficult to locate. Is it in Dropbox or Google Drive, on the computer in the office or the one at home, and what was the file's name and where in the filesystem hierarchy was it placed?
Of course today we have powerful search facilities but we still confront creating a query and even if it is successful it too often returns more than we want and much that is unrelated. Unfortunately, it will not bring back the context of previous use—the web of applications, notes, emails, slack conversations, etc.—associated with our activity with the searched-for item.
In an earlier time, we mainly worked in one place, an office. Although we might take a few papers home for an evening, home was disconnected from the office. Our books, papers, and notes were in the office. They were organized and placed in filing cabinets. Stu Card once described office(Card et al., 1991)in terms of the cost structure of information access.
He used the example of an office worker as shown in Figure 1. Information is available in the notepad on the desk, through the computer terminal, in the papers piled or carefully organized on the desktop, through other people using the telephone, from books in the bookcase, and papers in the filing cabinet. The media take different forms—from paper documents to machines to people—but each piece of information has a cost associated with finding and accessing it. Looked at abstractly, the office, at any moment, is characterized by a cost structure over the information in it. What is usually meant by an organized office is one with a cost structure arranged to lower the cost of information-based work processes performed within it. File cabinets, desks, filing systems, and computer-based information retrieval systems can be thought of abstractly as just means for changing the cost structure of information.
Figure 1. An Office Organized to Have an Efficient Information Cost Structure
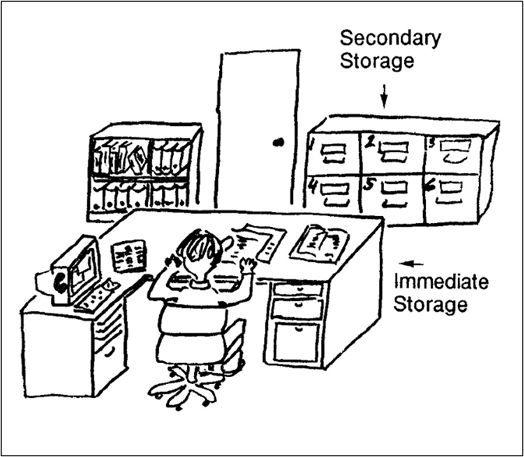
A significant component of the cost structure of information access is cognitive, the mental effort required to access or use the information. Sometimes the effort is so minimal it is not even noticed. For example, skills like reading are automated and the meanings of words happen with no apparent effort. Other times there is a feeling of friction, what one might characterize as a viscosity of information access. Access can also feel pleasantly frictionless such as when a long web address is suggested as you begin to type it or a directory where you recently saved a file is made available when saving another file. The feeling of friction comes from cognitive effort and if it is beyond some threshold it can feel more like an interruption and a shift to a different task.
Since activities are multilevel, friction can exist at multiple levels. We may have forgotten the name of someone we want to reference in an email, or in writing a paper we may feel the argument we are making is not compelling and we need to restructure and strengthen it. One involves a simple name retrieval. The other can involve a process of complex logical analysis and a search for and assembling data and arguments to provide support. Some of the friction can seem a necessary part of the task and other aspects less so. Many of the advances in applications and interfaces have come from removing friction such as spreadsheet applications easing calculations or highlighted searched-for terms in a document making them easier to locate. Friction we thought was a necessary component sometimes isn't. Enabled by recent AI advances, we see an astonishing range of examples of removing or minimizing friction and easing tasks, from providing writing suggestions to being able to use natural language to request an AI agent to write a program to accomplish a task or to generate an image drawn in a particular style.
In addition to the potential of AI to ease our tasks, the location of our workplace itself is changing. Sometimes we work in an office but often remote from it. Wherever we are, our information workspace is now typically confined to the screens of devices and lacks the expansiveness of physical desks, with space to lay out and view all the pages of a paper (sometimes extending onto the floor) or to easily organize and position information in useful ways. We still often feel the need to augment displays by using paper and whiteboards. In addition, screenbased arrangements are ephemeral, lasting typically only for the duration of a work session and certainly not available a week or a month later when we return to an interrupted project.
Although we continue to make use of our physical workspace—placing post-it notes on our displays and printing paper versions of documents and arranging them within reach to ease consulting them—our primary workspace now is on screens, typically consisting of multiple application and document windows, sometimes arrayed across multiple displays, with usually a primary browser window with many tabs. Applications have evolved over the years to provide excellent support for individual tasks such as spreadsheet calculations, formatting a document, or drafting an email but the vast majority of our activities, especially important ones, not only involve accessing multiple websites, applications, and files, and communicating via email, slack, and other applications, but they also take place over extended periods.
Today, networked information systems—spanning from the omnipresent cellphone to the complex web of computer systems that pervade and shape modern life — connect our activities to ever-expanding information resources. Yet despite tremendous advances in computational capacity and connectivity, computer-mediated activities and the spaces where we think are increasingly fragmented, lacking contextual, spatial, and temporal structure. The question I want to address is how should a place to think be designed in the new information age?
Designing a Place to Think
For far too long we have conceived of thinking as something that happens exclusively in the head. Thinking happens in the world as well as in the head. We think with things, with our bodies, with marks on paper, and with other people. As we have described above, increasingly we think with computers. Here information is displayed on screens as we work on tasks ranging from scheduling a meeting with a friend to accomplishing extended-duration activities such as writing this paper.
Ideally, these activities and collaborating with others should be efficient, fluid, and natural, taking full advantage of computer capabilities to augment our thinking and communication. I argue that to accomplish this collaboration and information activities must become native features of computer systems, in the same way that files or applications are today. To achieve this goal will require inventing new mixed physical and digital collaboration spaces (what we term below human-centered information spaces) that do not simply replicate (Hollan & Stornetta, 1992) the physical world in virtual environments but enable individuals and co-located and/or geographically distributed teams to work together smoothly and efficiently.
Beyond this technological challenge, we must also address sovereignty and societal challenges by creating the conditions for interoperability between communication and sharing services in order to open up the private walled gardens that now require all participants to use the same services and enable new players to offer solutions adapted to the needs and contexts of use. Users will thus be able to choose combinations of potentially "intelligent" tools and services to construct and tailor places to think that meet their needs without compromising their ability to interact with and share information with others. By making these services more accessible to a wider population, this will also help reduce the digital divide.
The fundamental premise of our vision is that the design of a place to think should be derived from cognitive principles. Since we are fundamentally spatial creatures, it must be spatial. Here we agree with Tversky that "spatial thinking, rooted in perception of space and action in it, is the foundation1 for all thought." (Tversky, 2019, p. 3) It also must be spatially expansive to contain all we need to represent, multiscale to allow different semantic levels of representation, and active to function dynamically as a partner. A place to think should be organized not in terms of applications, documents, and files but in terms of activities. It should be a place that persists over time, is sensitive to context, and is readily accessible when needed.
Of course, the need for a modern integrated workspace has been recognized by others and currently, there are many attempts such as Microsoft Office and Google Workspace to integrate applications, as well as note-taking tools such as Notion, Obsedian, Muse, and many others, attempting to provide integrated management facilities. Our goal here is to describe the fundamental design characteristics needed to create a productive, convivial, and ideally beautiful place to think, what we term a human-centered information space.
A Human-Centered Information Space
"The computer desktop was an amazing design for its time, but does not reflect the complexity, flexibility, and sociality of human activity...Eventually, we will have to reorganize the desktop to reflect the complex mix of activities users engage in and move beyond the rigidity of separate applications and files-and-folders." (Kaptelinin & Nardi, 2009) -- Bonnie Nardi
A human-centered information space is both an idea, and a computational environment. It is the idea of a spatial cognitive workspace—a desktop for intellectual activity—reified as a computational environment that actively supports the coordination of information-based work. Specifically, the information environment should develop awareness of the history and structure of a user's action: how she accomplishes activities through discrete tasks across devices, programs, and working sessions. Through use, information in the environment accumulates structure and context: not only who accessed it and when, but concurrent activity and semantic relationships to other related information and activities.
The context and history of activity should drive the behavior of information. To the user, her information should seem alive, have awareness, know where it came from, how it got there, what it means—and behave accordingly. These representations and interactions will in turn guide the user's future action such that the struggle of resuming interrupted work is eased. It is crucial to emphasize a human-centered information space will not replace the user's ecosystem of documents and applications, but be a separate space linked to them, acting as a home, a control center, a multi-modal but fundamentally 'spatial workspace' where information across applications will converge with visual features and active behaviors that support the user in not only completing her tasks, but accomplishing long-term overarching activities. To make the notion of a human-centered information space more concrete we sketch a scenario.
Scenario: A Human-Centered Information Space
Samantha leads a microbiology research group. She has just returned from a conference and is ready to continue writing a paper she started before her trip, but is struggling to remember where she left off. As an early adopter of technology, Samantha has been using a new prototype system—a human-centered information space. She thinks of the software as a spatial workspace, a separate zoomable space of representations of her past activity with links to activity-associated documents (e.g., articles, email messages, web pages, notes, sketches, and analyses) and applications. Information in the space is active, powered by sets of rules and AI agents, it is aware of when and how information was accessed and able to show the contexts of past interactions and summarize, filter, and depict activity and information at multiple semantic levels.
To get back to her paper, Samantha browses an automatically created event-based timeline of her past working sessions. She vaguely remembers searching the web for a specific article, but now can't remember if she found it or why she was searching for it. She scrubs through visual landmarks in her activity history to an event before she left for the conference. This timeline, like the workspace itself, is multiscale, enabling her to move up and down levels of abstraction. She shifts to a level where only landmarks of major activities (e.g., a session of data analysis or writing) are displayed, and finds the writing session. When she selects it, a visualization of the session expands to reveal the article she was searching for in the context of other applications she was using at that time. This reminds her she did find the article and she sees she also downloaded other related articles.
When she hovers over this article collection, visual and textual summaries appear. The visual summary is a montage of images from the documents. She moves down a level of abstraction, and PDFs appear elided based on her past activity, showing only passages she read carefully or highlighted. She realizes she had skimmed a few, and identifies one she read more deeply. When she moves down another semantic level for this article, the workspace provides an option to reinstate the past context. She accepts and the space rearranges to show her editor beside the other applications and automatically scrolls to the places in each where she had last been active. She appreciates that this transition is animated to ease understanding and remembers how easy it was to tailor this behavior using natural language. This workspace is where she typically accesses AI agents because her interactions with the results are summarized and maintained in the context of her activity.
Taken back to the specific context of her earlier writing task, she triggers a movie-like replay of her activity that resembles the quick clips shown at the beginning of a series on TV to remind one of past episodes. She suspects this animation would be difficult, if not impossible, for anyone else to follow, but because it is derived from her history, it is evocative for her just like the spatial location of piles of paper on her physical desk have meaning to her but not to others. In the replay, she sees herself navigating back and forth between reading the article and writing the paper. She suddenly feels as though she has been transported back in time, even remembering her earlier train of thought. She is now ready to resume writing.
Of course, this idealized scenario glosses over myriad complex research issues. Designing a dynamic personal multiscale information space linked to the complex world of existing information and capturing and representing histories of interaction confront a host of challenging research questions: How is this parallel information space created and linked with existing information? How are multiscale representations of information and activity created? How are they depicted and arrayed in the space? How are histories captured and contexts recognized? What are the nature of the rules and AI agents that provide the dynamic information behaviors and how do they operate in ways sensitive to tasks and contexts? To address these questions and design the human-centered information we envision will require large-scale scientific collaboration.
Figure 2. Collaboratory for the Design of Information Work (CDIW) Network of Networks
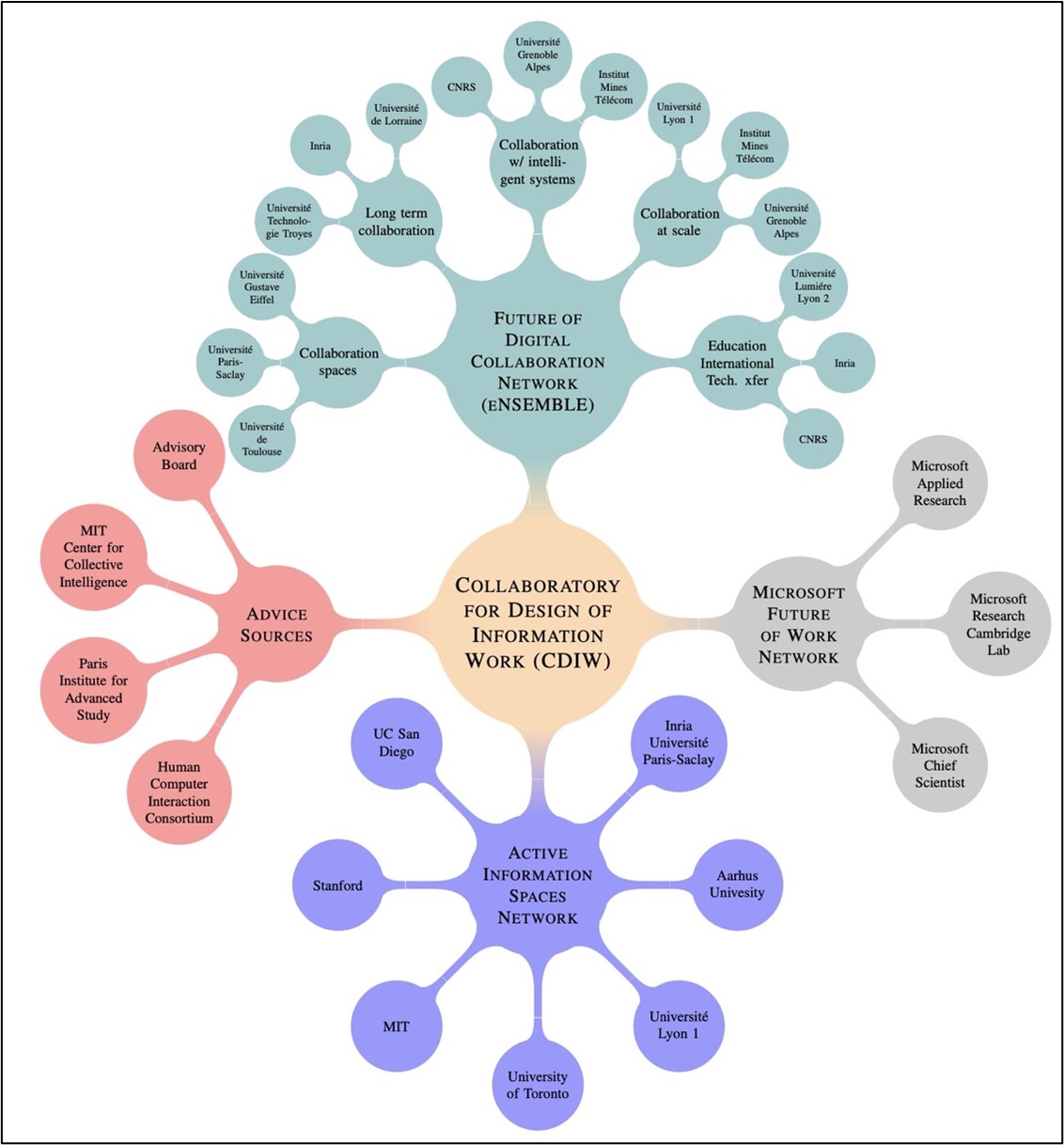
Note. CDIW connects the original Active Information Spaces network to the eNSEMBLE Future of Digital Collaboration, spanning 80 research groups and 30+ universities in France, and the Microsoft Future of Work network that is distributed across research labs in the U.S. and Europe.
Collaboratory for Design of Information Work (CDIW)
We have recently proposed2 an international research network, the Collaboratory for Design of Information Work (CDIW), to address these research questions. We argue that today's most significant and urgent scientific problems are global in scale and inexorably entwined with information technologies. Solutions will thus require both technological innovation and international collaboration. Networked information systems—spanning from the omnipresent cellphone to the complex web of computer systems that pervade and shape modern life — connect our activities to ever-expanding information resources. Yet despite tremendous advances in computational capacity, connectivity, and artificial intelligence, computer-mediated activities remain fragile, fragmented, and frustrating. Addressing this challenge by fostering human-technology partnership is the integrating theme of the CDIW network. We argue that a core challenge for the future of collaboration and information work stems from the unquestioned presupposition that information is passive data, disconnected from the rich context of human activity. Members of the CDIW are united by the shared vision of enabling entirely new classes of solutions by advancing beyond the legacy document-and-application-centered paradigm of current systems and the walled gardens and information silos it entails. Initiated by a network of research labs in the U.S. (UC San Diego, MIT, and Stanford), Canada (Toronto), Denmark (Aarhus), and France (Inria and Paris-Saclay) focused on active information spaces, the CDIW has coalesced into a network of networks with clearly articulated research objectives beyond the reach of any individual member and strategic linkages to the recently funded (38M€) French eNSEMBLE: Future of Digital Collaboration network and Microsoft's Future of Work network focused on information work in collaboration with AI.
The broader potential impacts of the CDIW arise from the potential to radically improve information activities, reshaping not only the way we use but how we think with computers. The direct outcomes of our research agenda will improve the productivity and well-being of information workers, with a primary focus on digital collaboration, information visualization, and similar extended-duration information-rich activities. To accomplish this, our network directly engages with the complex socio-technical issues underlying challenges of the modern global information workplace. Here we align with NSF's commitment to growing convergence research and building capacity through international exchanges, skills training, shared mentoring, and inclusive outreach. These activities will accelerate the pace, scale, and impact of research across the individual labs of the CDIW networks while recruiting and training the next generation of US-based researchers steeped in the advantages of interdisciplinary international collaboration. To advise the CDIW, we involve the long-standing and influential U.S.-based Human-Computer Interaction Consortium (HCIC) of university and industrial researchers, the Paris Institute for Advanced Studies, a transdisciplinary research center with experience facilitating the emergence of networks of young international researchers working on major societal issues, the MIT Center for Collective Intelligence that explores how people and computers can be connected so that collectively they act more intelligently, and Microsoft's Office of Applied Research as members of an advisory panel to help nurture, expand, and ensure sustainability of the CDIW network.